
| Data | 16位 | 32位 | 64位 |
|---|---|---|---|
| char | 1 byte | 1 byte | 1 byte |
| int | 2 bytes | 4 bytes | 4 bytes |
| float | 4 bytes | 4 bytes | 4 bytes |
| double | 8 bytes | 8 bytes | 8 bytes |
| long | 4 bytes | 4 bytes | 8 bytes |
| short | 2bytes | 2bytes |
字节对齐的细节和编译器实现相关,一般而言有3个准则。
结构体变量的首地址能够被其最宽基本类型成员的大小所整除。
结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(Internal Adding)。
结构体的总大小为结构体最大基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(Trailing Padding)。
(1)例1:简单体验
1 | struct name |
例1:原理图:(这里,编辑器会根据结构体中最大字节的数据类型给内存等分成小段,比如下图中蓝色与绿色的荧光笔就代表着分成了的其中两段)
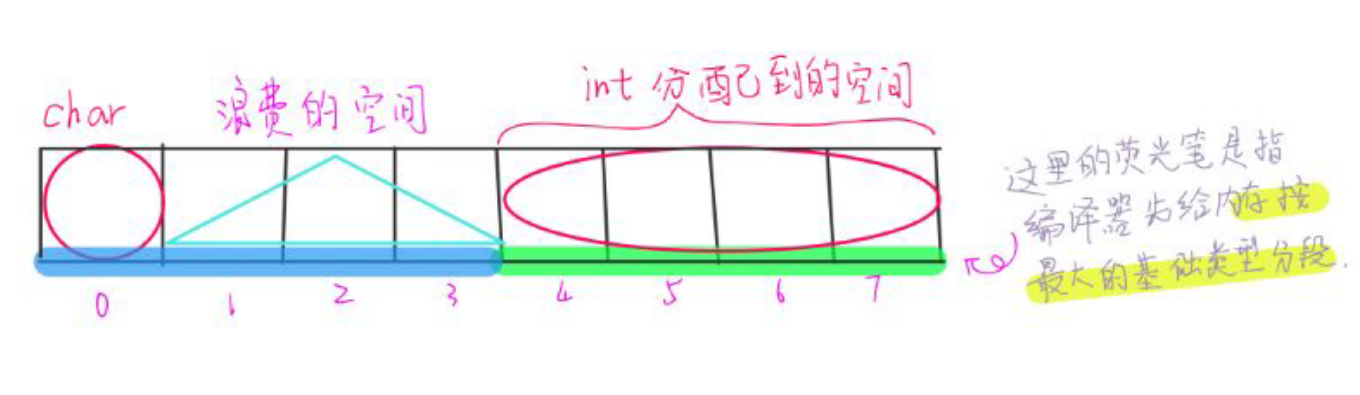
(2)例2:数据类型的顺序对结构体内存大小的影响
1 | struct name |
例2:原理图
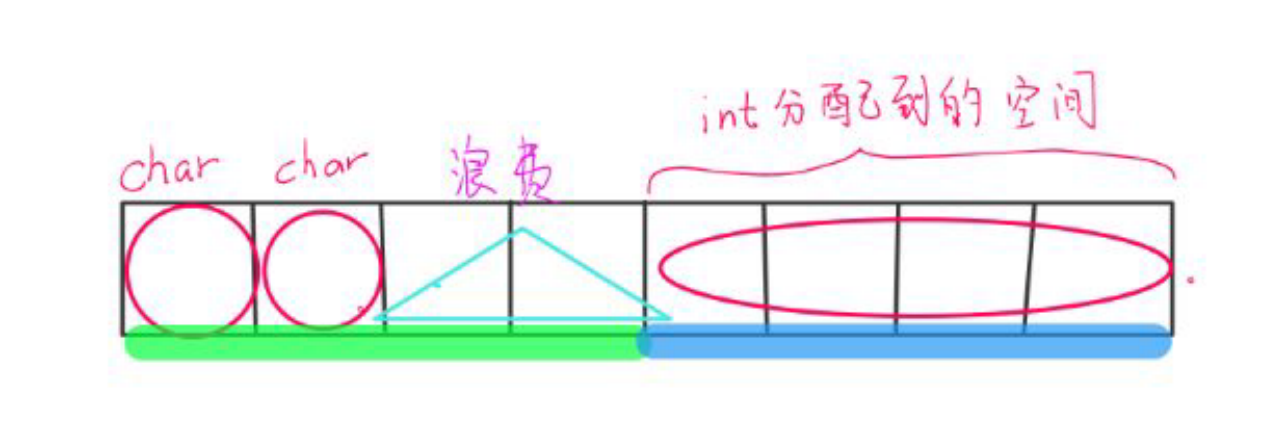
例3:
1 | struct name |
例3原理图:
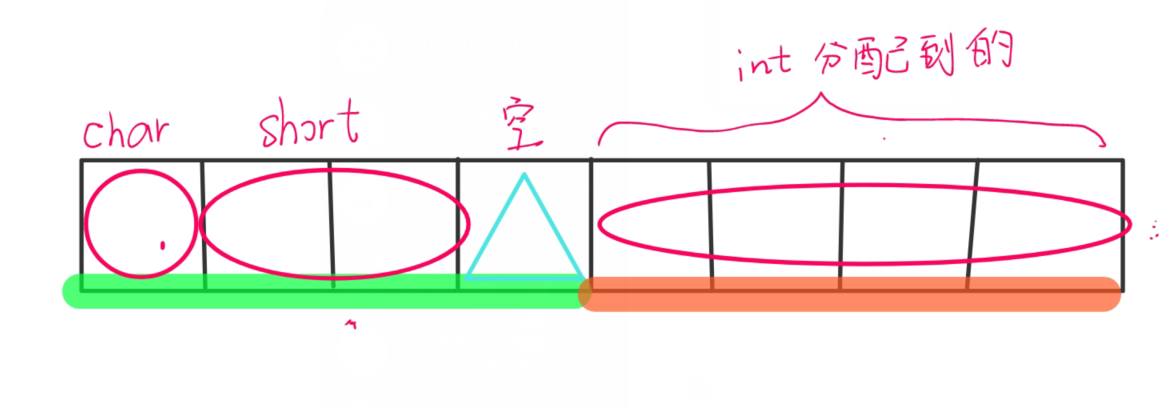
例4:
1 | struct name |
例4:原理图:
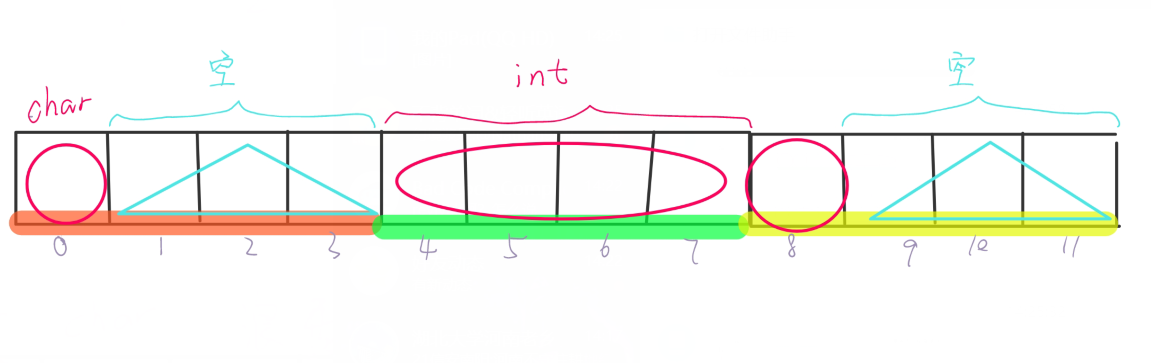
很显然,数据类型的排列的顺序不同也会影响到结构体的内存空间
例4:
1 | struct student |
例4:原理图
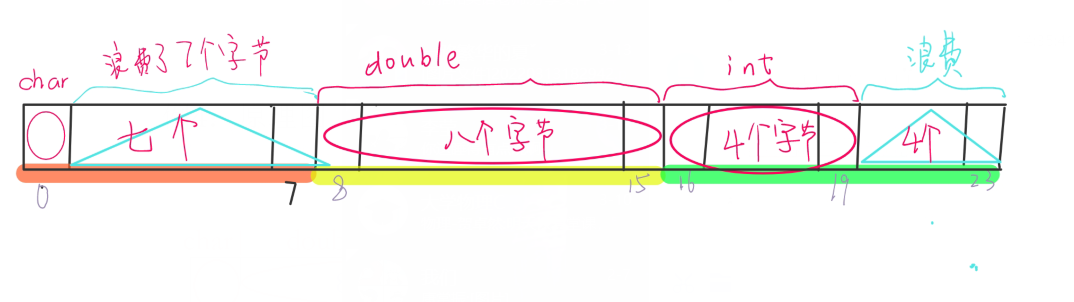
例5:带有数组的结构体
1 | struct student |
注意:最大的基本类型double b而不是char a[10]
例5:原理图
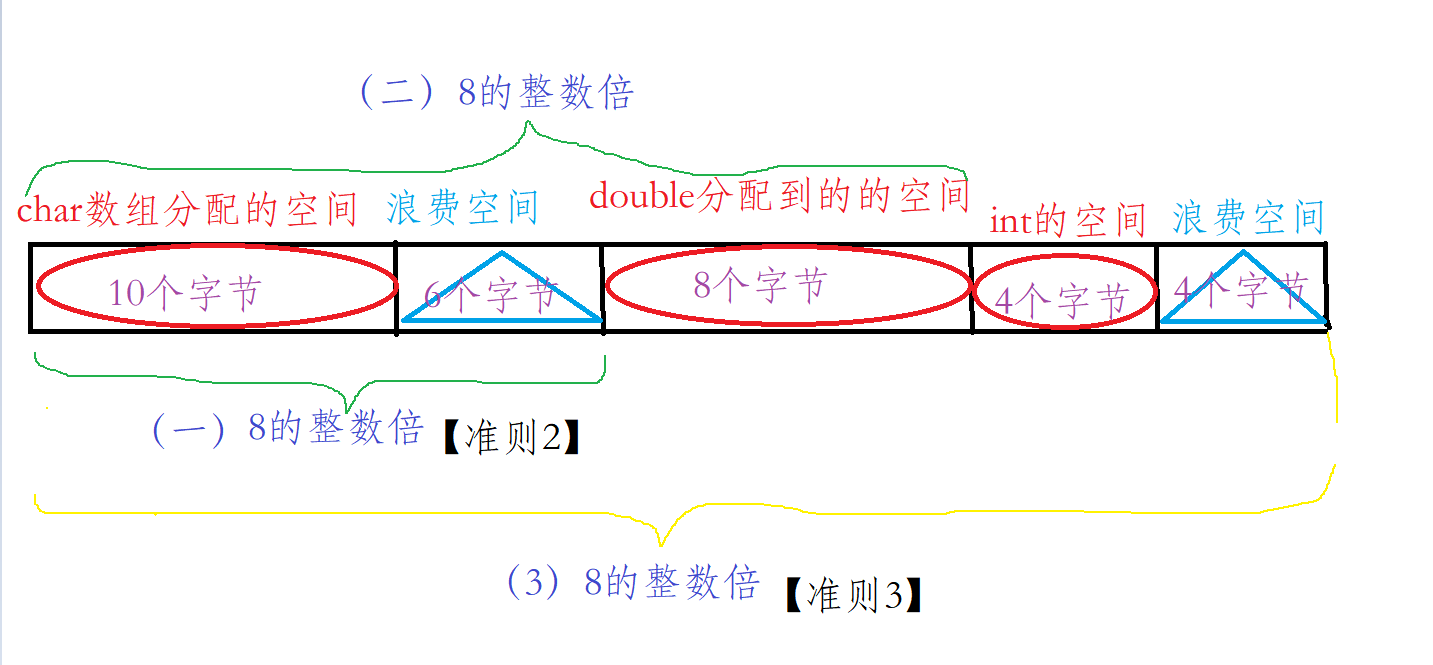
例6:
1 | struct student |
例6:原理图
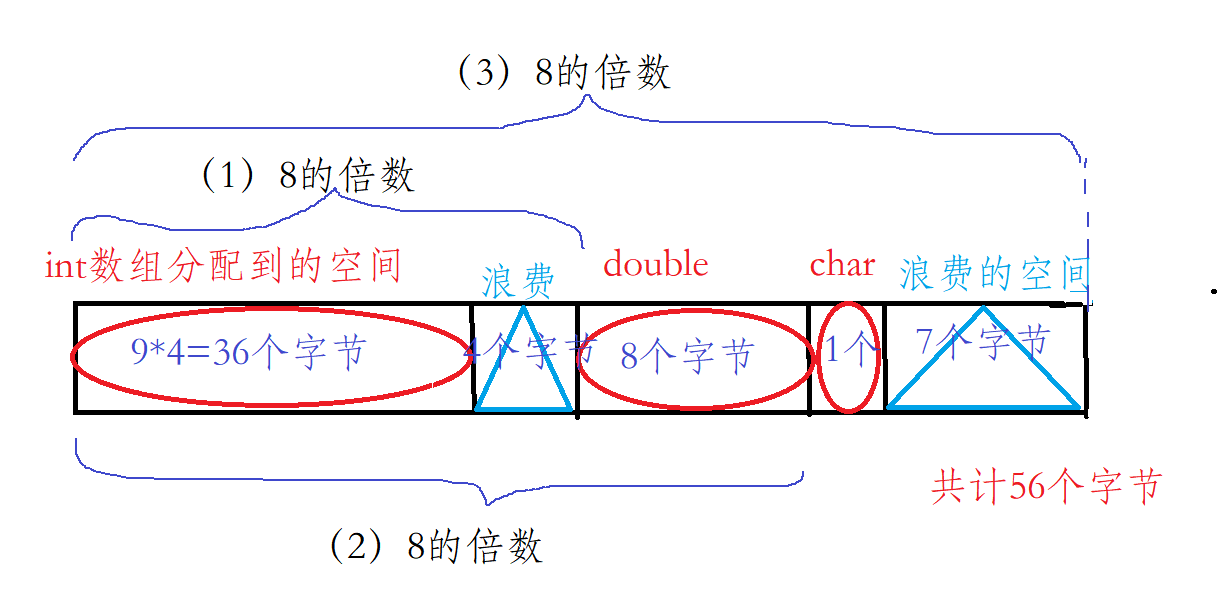
#pragma pack(n) n为整数
- n 就相当于上面的最大数据类型的字节